As many of our users know, Full-Text RSS, our article extraction tool, relies on a number of site-specific extraction rules which we maintain in our GitHub repository.
These extraction rules were initially imported from Instapaper (before it was sold, when they were still publicly available). And since then we’ve done our best to update them and have received many contributions from our users (thank you!).
But while the repository has grown over time, we’ve had no system in place to check whether the rules it contains are still effective. Or if the sites they were created for still alive.
Well, now we have such a system. It’s fairly basic and still experimental, but we think it’s a good start. It runs a number of checks periodically, using the site configuration files in our repository, and produces a report listing the ones which need attention. Here’s what it checks for:
Presence of at least one test URL per site
To determine if Full-Text RSS can extract content, site config files should contain at least one test URL. So if one is not present, we’ll include it in the report.
Match between test URL hostname and site config filename
A site config file called example.org.txt is only loaded when we process URLs from example.org. So this test is to make sure that the test URL inside the site config file is one which will actually load the site config file in which it appears.1
Valid response from test URLs (200 status code)
This test is used to make sure the test URL is not dead. If it is, it could mean one of a few things:
- The site has been redesigned, breaking old URLs. If so, the extraction rules might need to be updated, and a new test URL entered.
- The site is the same as before, but the page in question is no longer available at the URL. If that’s the case, a new working test URL should be entered.
- The site is no longer alive. In which case the site config file should be deleted.
- The site is not dead, but it’s temporarily unavailable.
Expected content
Let’s say we got a valid response from the test URL in the test above. This doesn’t actually tell us if Full-Text RSS can successfully extract content from that URL, only that the request has succeeded (the server has returned a 200 OK status code). So now we look for a new site config directive called test_contains. This should contain a small chunk of text that we expect to find in the article. If this directive is present in the site config file, we will pass the test URL to Full-Text RSS for it to extract the article content from the page. We’ll then check the extracted content to see if the chunk of text contained in our test_contains directive appears. If it does not, it will be flagged in the report.
As this is a new directive, most of the site config files do not contain it. But we’ve started adding them to a few sites. Here’s what it looks like (example from theguardian.com.txt):
test_url: http://www.theguardian.com/world/2013/oct/04/nsa-gchq-attack-tor-network-encryption
test_contains: The National Security Agency has made repeated attempts to develop
test_contains: The agency did not directly address those questions, instead providing a statement.
test_url: http://www.theguardian.com/world/2013/oct/03/edward-snowden-files-john-lanchester
test_contains: In August, the editor of the Guardian rang me up and asked if I would spend a week in New York
test_contains: As the second most senior judge in the country, Lord Hoffmann, said in 2004 about a previous version of our anti-terrorism laws
The test_contains directive should appear after a test_url directive. It can appear multiple times. If it does, we’ll associate each one with the test URL that appears above it. So you can, for example, take a sentence from the beginning of the article and one from the end. Our tests will look for both of these in the extracted content and warn you if one does not appear.
How does this work?
The tests are automated. We grab the latest set of site configuration files from our GitHub repository roughly every 48 hours and then start looking through the files in batches to identify problems.
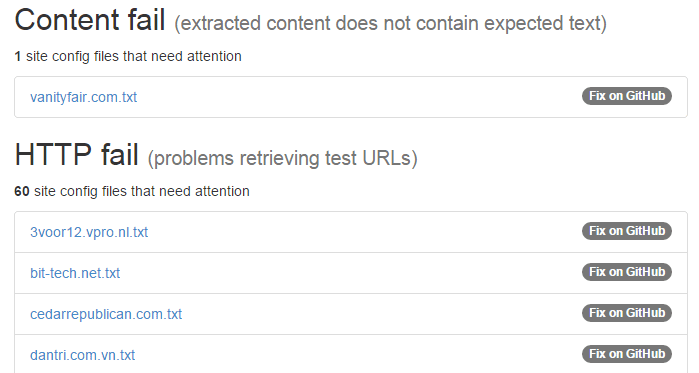
Problems are reported in 3 categories:
- Content fail: extracted content does not contain expected text
- HTTP fail: the test URLs could not be retrieved
- Warnings: no test URL present for site, or a possible mismatch between test URLs and site config hostname
In each category you will see a list of site configuration files. Clicking on one will give you more information on what exactly failed. Next to that link you will also find a ‘Fix on GitHub’ link which will take you directly to the GitHub page in our repository associated with that site configuration file. This allows you to edit the file and suggest a fix using GitHub’s web interface.
Try it out
You will find test results here: Full-Text RSS site config tests.
We’d very much appreciate fixes to these site config files. And of course the whole repository of extraction rules is in the public domain – free for anyone to use.
If you have any feedback, we’d love to hear it. Thanks!
- For feed URLs, the hostname test might produce false positives. For example, the feed for example.org might be hosted at feed.example.org or feedburner.com. These are still valid test URLs, even though there’s a mismatch between the test URL hostname and the site config filename. For that reason, we currently do not run this test on test URLs which contain ‘rss’ or ‘feed’ in the hostname. In the future, we’ll try to separate the web page URLs from feed URLs in the site config files so we can handle these cases appropriately. ↩︎